一个任何样本量下比UMVUE还要“好”的有偏估计量!这一颠覆经验认知的反常现象,被称为Stein's paradox。
本人没有能力开拓什么,只能综合前辈们的观点尽量感悟;没有打算、更没有能力深入研究收缩估计,不过是对Stein's paradox的奇怪现象感到诧异,来了兴趣,所以查阅多手资料后写下了本文。
Estimation with Quadratic Loss
ESTIMATION WITH QUADRATIC LOSS - Yale University
1961年Willard James与Charles Stein的文章,在这里James-Stein估计被首次提出,点击此处下载论文。
大规模推断讨论班:经验贝叶斯与 James-Stein 估计量 - GitHub
这篇文章非常系统地从经验Bayes观点引出了Stein理论与Robbins理论,读完后收获颇丰,本文也有所参考。也说明了,所谓“频率学派”、“贝叶斯学派”的对立,“贝叶斯世界观”等描述并不准确,频率方法和Bayes方法不是水火不容的,统计学发展到今天,他们本身的界限就比较模糊。
赵世舜. 矩阵加权估计及James-Stein估计的再研究 [D]. 吉林:吉林大学,2006.
感谢这篇博士论文为我提供的帮助,第二章定理证明的思路是源自于这份文献的;好像在2017年赵已经在吉林大学数学学院升任教授职务了。由于知网下载文献得付费,我用学校的渠道下载了下来并上传到了网站,点击此处查看这篇论文。
本文不是正经的论文,懒得划出具体的引用😊以上文献本身亦引用了较多文献,如果有兴趣,不妨也读一读。
本文用到了一些缩写:MLE指极大似然估计,UMVUE指一致最小方差无偏估计,MSE指均方误差,G-M定理指高斯-马尔可夫定理。
the James-Stein Estimator
众所周知,
但是,这并不意味着样本均值在任何意义下都是最“好”的!1961年由Willard
James和Charles Stein基于1956年Charles
Stein提出的早期版本所改进得到的James-Stein
estimator(下简称JSE)就是这样一个例子,当用当p=2时显然JSE等价于样本均值。
这个结论第一眼看起来真的出人意料!这似乎违背经验,毕竟在我们的印象中,寻找、构造UMVUE一直都是统计学家的“毕生追求”,然而JSE的出现却表明,在非无偏估计家族中、在某些情况下,我们或许有比UMVUE更好的选择(这具体取决于我们在特定情境下如何定义“损失”标准)。
这也深刻地说明了,UMVUE其实并没有设想的那般“绝对的好”,当我们把眼光放宽到无偏估计,可能还有更“好”的估计在等着我们发掘。JSE就揭示了,当维数大于2,样本均值作为UMVUE就未必还是最好的估计!换句话说,在低维可容许的样本均值,在高维是不可容许的,这侧面印证了低维直觉放在高维中很可能是错误的,高维统计中还有很多这样的例子。
Tip:
由于正态分布的样本均值仍服从正态分布,为简便起见,后文中如若未做特别说明,则只考虑
James-Stein型估计的风险
这里将按照赵世舜在其博士学位论文中所给出的,仿照1981年Stein、1990年Brandwein与Strawderman给出的较为简单的证明,证明当
看过1961年Willard James与Charles
Stein的论文原文,这部分没有看懂,所以不按那最古老的方法证明风险一致地小了。
引理 1 (成平 等,1985) 当
定理 1 以二次损失定义风险,设
首先容易知道,
值得说明的是,即使
可视化JSE与MLE的估计效果
通过下述代码直观地可视化JSE与MLE估计效果上的差异,
1 | import numpy as np |
为保证结果可复现,设置种子np.random.seed(1),部分测试样例如下表:
| N |
N=1 1 |
N=20 1 |
N=10np.repeat(1,50)4 |
N=1000 1 |
N=5 1 |
N=1np.random.rand(10)1 |
|---|---|---|---|---|---|---|
| MSE(JSE) | 0.531834 | 0.030650 | 0.321131 | 0.001485 | 0.000059 | 0.290441 |
| MSE(MLE) | 1.097236 | 0.030969 | 0.373426 | 0.001487 | 0.122682 | 1.291636 |
由于np.random.rand(10)作为总体均值,观察样本量从1到30时二者的变化。
1 | import matplotlib.pyplot as plt |
可视化结果如下:

可以看出,当样本量较小的情况下,在MSE准则下JSE是明显优于样本均值的,随着样本量的增大二者差异逐渐减小,均向
抛开MSE准则不论,从数字的差异上也能直观感受到JSE更加“精准”。对正态总体
JSE: [ 0.20985719, 0.09654112 ,-1.07700422], the MSE: 0.404433
MLE: [0.27568837, 0.12682561, -1.41485522], the MSE: 0.697968
显然,JSE更接近总体均值
当总体均值的长度与方差较小时,他们的变化对JSE与MLE间优劣的差异几乎没有影响,
- 二者MSE随着总体均值长度的增大而稳定增大且速率越来越快;
- 随方差增大震荡增大.
以下为随机抽取的可视化典型样例:

|

|
为探究何种因素会使影响JSE与MLE的相对估计效率,记MLE与JSE的MSE比值为

|

|

|

|

|

|

|

|
|
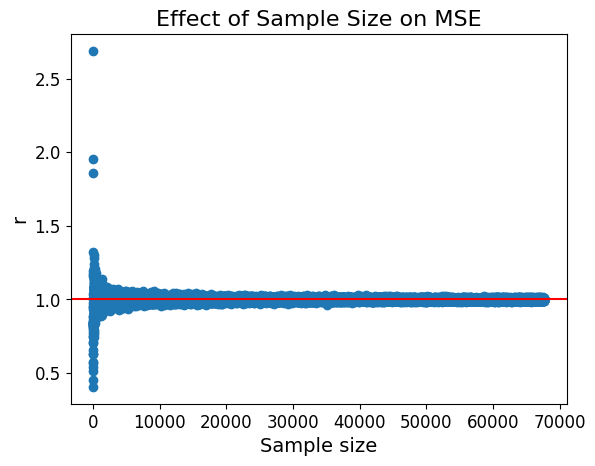
由此可知,在其余条件控制不变的前提下,
伴随
的增大, 很快收敛于 ,二者无明显优劣; 伴随
的增大, 趋向于 ,但在 较小时JSE优于MLE,随后优势被渐渐削弱。考虑到 控制在 、样本量 控制在 (图中是 的情况),当 充分大时讨论估计的优劣没有太大价值,因此可以认为JSE优于MLE; 伴随维数的增大,
将收敛到一个明显小于 的值,JSE显著优于MLE; 伴随样本量的增大,
在 附近跌宕起伏且波动幅度不可忽视,估计相对优劣的变化不规律,但是在样本量较小时JSE仍优于MLE,随后优势被渐渐不明显; 无论如何,在绝大多数情况下,JSE的平均风险不超过MLE;
模拟中并未测试但不排除可能的影响因素:变异系数.
Shrinkage Estimation与正则化
JSE是一种Shrinkage estimation,中文一般译作收缩估计、压缩估计。收缩估计第一次在Willard James和Charles Stein的《Estimation with Quadratic Loss》中出现,正是在这篇文章中提出了本文的对象JSE,不过“收缩”一词直到1983年Copas在《Regression, Prediction and Shrinkage》中才被提出,在这篇文章中他这样定义了收缩:
The fit of a regression predictor to new data is nearly always worse than its fit to the original data. Anticipating this shrinkage leads to Stein‐type predictors which, under certain assumptions, give a uniformly lower prediction mean squared error than least squares.
压缩估计通常会以偏差的较小增长换取显著更小的方差,这被称为方差-偏差权衡策略;换句话说,用均值的偏移换取更小的置信区间。收缩在Bayes推理和惩罚似然推理中是隐式的,在James–Stein型估计的推理中是显式的;JSE可谓是收缩估计的开山之作,同为收缩估计的还有岭估计(ridge estimator)、LASSO估计以及他们的一系列改进,这些都是比较新的方法。
关于收缩估计还有个更简单的例子,通常样本方差通过
从正则化的观点看,收缩是一种正则化惩罚的形式,也可以说正则化是实现收缩的手段之一,通过(将参数向
- JSE的形式为
,令 为shrinkage factor,那么JSE可以看作在样本均值的基础上进行了“收缩”,形式上为 ,收缩程度由收缩因子 决定: - 相较于样本均值将每个维度的分量分开计算均值,JSE把分量们整合起来进行估计.
尽管JSE如此“年迈”,但在很多情景下仍发挥着不可或缺的重要作用,后续提出的许多新压缩估计也是基于JSE的。不过据李婷婷老师所言,似乎收缩估计这块并没有太多人在研究了。看起来,起码是我校是没有老师在做的。
JSE的经验Bayes推导与解释
最初JSE是由Willard James和Charles Stein通过经验Bayes估计(empirical Bayes methods)导出的,正如前文所述,那时还没有诞生shrinkage的概念。在此,我希望通过经验Bayes的解释,让JSE在Bayes框架里看起来更自然。这也说明,选择合适的先验,Bayes估计可以比MLE更“好”——尽管MLE本身也和Bayes框架是兼容的。
与前文类似地,只考虑
既然
根据解出的后验分布,可以得出在先验
现构造
最后,上文的推导中运用了自由度为

相关文献与扩展阅读:
《经验贝叶斯与 James-Stein 估计量》这篇文章我认为是写得很不错的,有丰富的例子、数据与图像帮助讲解,甚至还介绍了一下Stein的为人。作为免费公开的资料,竟然被国内互联网各大毒瘤文库作为收费下载的内容;作为GitHub上的共享资源,用百度却根本搜不到,还是后来我用Google才找到这里;试了试国内版Bing,Bing也将这篇文章的GitHub链接放在了搜索第一位。中国的这些互联网厂商,过于抽象,过于逆天,吃相难看。我将文章下载并上传到这里了,如果不方便访问GitHub,可以点击通过下方的关键词阅读文章。
将JSE推广至更佳的矩阵形式
赵世舜在博士学位论文中完成了这项工作,他证明了可以将JSE推广至矩阵形式,而且保持了良好的性质。
推广的思想与动机是,根据随机变量二次型期望理论,当
赵世舜证明了JSE的矩阵推广形式拥有至多与JSE相等的的MSE,下展示赵世舜博士学位论文中的这一部分结果:

此外,还有:

该定理的证明参见原文。
JSE与OLS
如果线性模型的残差被假设服从正态分布,很容易把JSE应用到线性模型回归系数的估计中。推导与证明的过程不再赘述,仿照着上文即可,只给出结果:
线性模型的JSE推导与诸多性质的证明本文不再深究了,可以参考:
- James-Stein estimation,若无法访问则请点击此处;
- James–Stein estimation problem for a multivariate normal random matrix and an improved estimator
本文到这里正式结束了。或许后来的我随便翻看着本文,会感慨:原来读本科的时候,我还有毅力去尝试着学习。
本文的写作中参考了许多相关文献,真正的原创大概只有第三章的可视化与第五章的证明,事实上第五章也只是在其他文献基础上做了推广的推导,在原文中只展示了