: state, a random
variable. Let the state space be , and let the random variable
represent the state at time
: action, a random
variable. Let the action space be , and let the random variable
represent the action taken at
state
: reward, let be the reward obtained
immediately after taking ,
namely
: discounted return, a
function, let be the discounted
reward obtained after taking ,
namely
: discounted rate, a
parameter that weighs the importance of future reward, . The closer is to , the more farsighted the algorithm is.
A bootstrapping instance:
: policy or strategy. A
policy is a conditional probability that specifies the probability of
taking any action in any state, denoted as . A policy can be stochastic or
deterministic. Policy is a Markov chain.
: state value, the average
return the agent can get starting from a state, is the expectation of
due to . If
, we consider to be better than for .
: action value, the
average return the agent can get starting from a state and taking an
action, is defined as
: a rate that
determines whether there is more exploitation or more exploration in the
ε-greedy algorithm, where the closer is to , the more exploration the algorithm
performs.
: a parameter, called
the step size or learning rate in the optimization algorithms
usually.
introduction
Markov decision process
temporary omission
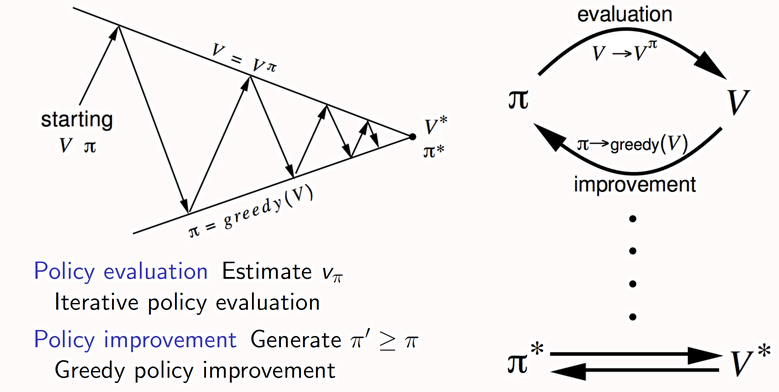
Bellman equation
The Bellman formula, utilizing the bootstrapping method to take
policy evaluation, can avoid calculate directly: where is a given
policy, so solving the formulas is called policy evaluation. Meanwhile,
represent
the dynamic model; what if the model is known or unknows (model-based or
model-free?).
It is hard to calculate for directly in reality (This involves
computing a numeral to which the numerical series converges). Using
bootstrapping, combining all expressions about for , we get the Bellman equation. Then solving the Bellman
equation can get all .
The Bellman equation is a system of linear equations, such as: Using the knowledge of linear algebra, it is not difficult to
know that the solution of the above equation is Tip: Calculating numerical series according to the fundamental
definition is feasible but inconvenient for complex situations, too.
Here is a case: In order to simplify the Bellman equation, we will temporarily
ignore details and focus on the macroscopic meaning. Let us rewrite the
parts in Bellman equation as then This formula illustrates the intuitive meaning of the Bellman
equation. Based on this, it can be expressed in matrix-vector form:
where ,
,
, and ,
is the state transition matrix.
the closed-form solution: Since solving the closed-form solution involves calculating
the inverse of the matrix , a large amount of
calculation may be required when the matrix dimension is high, so this
method is not considered in actual algorithm design.
an iterative solution:
Let this algorithm leads to a sequence ,
and we can prove that
In addition, the Bellman formula can also be expressed in terms of
action value as ,
which is equivalent to expressing it in terms of state value; in fact,
the average of all action values in state is equal to the state value of , namely
.
When the state values are known, the specific action values can be
obtained according to which means that the average return an agent can get starting
from a state and taking an action immediately in future, namely The state value is used directly to evaluate the strategy, and
the action value can show the optimal strategy. These are two sides of
the same coin of the Bellman equation.
Bellman optimality equation
Definition: a policy
is optimal if for all and
for any other policy
Bellman optimality equation: in matrix-vector form: To solve any equation that has the form of , we can consider the
Constraction Mapping Theorem, if is a contraction mapping. Just consider
a sequence where , then as . The theorem confirms the
existence and uniqueness of . Moreover, the convergence rate
is exponentially fast.
In fact, if we let , then hence is a
contraction mapping and the Bellman optimality equation implies a fixed
point . The algorithm designed
according to this idea is called the value iteration. The
specific process of this algorithm will be given in the next
chapter.
Optimal policy ,
at the same time
Here are 3 factors:
How to choose system model ?
How to design reward ?
What matters is not the absolute reward values, but their relative
values. If we let , we will get the same optimal policy and the
corresponding optimal state ,
How to set discount rate ?
The following chapters discuss how to efficiently calculate the
Bellman optimality equation to obtain the optimal policy.
dynamic programming
# model-based iteration algorithms
value iteration: This algorithm has actually
been given in the previous chapter using the Pythagorean theorem
Each iteration of this algorithm can be divided into two steps, with
and which is
given:
policy update where is
known and is
a greedy deterministic policy. It means:
value uodate stop the loop when
is smaller than a predefined threshold
value iteration
Tip: The above equation is not the Bellman equation, because only converges to
but does not
satisfy the Bellman equation. That is, we should distinguish the
following two equations, and the first of which is a Bellman equation:
1. ,
2.
In general, the closer the state is to the target, the earlier the
decision on the state is updated to the optimal strategy
policy iteration: policy iteration is based on
value iteration,
Given an initial policy ,
policy evaluation: calculate the state value of then get
Tip: To solve this equation (policy evaluation), we need to do a
sub-iteration here (value iteration) if we do not consider the
closed-form solution
policy improvement
we can prove is better
than and
Likewise
arXiv: Topological Foundations of
Reinforcement Learning
truncated policy iteration
Observe value iteration and policy iteration: In fact, in each
iteration, value iteration updates the policy and then replaces with the
one-step approximation of the Bellman
equation; in each iteration, policy iteration calculates the exact
solution of the Bellman equation for the policy and then updates the policy with
this exact solution, where the exact solution is usually obtained
through the infinite step approximation . The idea of truncated policy iteration is to
replace
with a finite-step approximation of the solution of the Bellman
equation. Therefore, value iteration and policy iteration can be
considered as special cases of truncated policy iteration, and truncated
policy iteration is a generalization of the former two.
On the basis of policy iteration, we only need to set the maximum
number of iterations of sub-iteration.
truncated policy iteration
When performing iterations,
generally speaking, value iteration converges the slowest and policy
iteration converges the fastest, but the time overhead is greater than
that of truncated policy iteration.
In fact, these methods are maintaining such a table:
Monte Carlo learning
# ε-greedy method
Step by step, our ultimate goal is to get the ε-greedy algorithm in
this chapter.
When model is unavailable, we can use data.
basic MC algorithm:
note the policy iteration / truncated policy iteration (all based on
the Bellman equation), Therefore, we can replace the exact
with an estimate obtained through samples (experience). This is the
simplest application of the Monte Carlo method. where is the sample
size and is the -th sample statistics of
The rest of the algorithm is the same as policy iteration / truncated
policy iteration. Since there is no other change based on policy
iteration / truncated policy iteration, the convergence of the algorithm
can still be guaranteed so far.
MC basic algorithm
episode: In actual calculations, will only take the discounted
reward of the first steps. The
mathematical definition of is an
infinite series, and the th term
represents the weighted reward that can be obtained by making transitions under the condition of
starting from state and taking
action . When using Monte Carlo
estimation instead of mathematical expectation, we can only take the
first few terms for estimation because we do not have infinite time to
calculate infinite sums (discounted rewards for infinite transitions).
On the one hand, the first few terms of the series are the rewards for
the most recent steps of the transfer, the data is more robust, and they
are also the most important steps of transition at the moment; on the
other hand, due to the existence of discounted rate , the first few terms contribute
the most to numerically.
Generally speaking, the later the term, the smaller the impact on . We call the
set of the most recent -step
transitions according to the current strategy an episode, where is the episode length. Note that an
episode is obtained by transitioning according to a certain strategy,
not "completely random".
The simplest and most direct way to calculate is to find an
episode starting with action in
state , and then calculate the
average. This method focuses on one state and is called initial-visit,
which is very inefficient.
MC exploring starts:
Mainly mention two improvement methods for basic MC algorithm
here,
Use data more efficiently
Only one value is estimated for one episode, and the data utilization
is obviously inefficient. To solve it, we can apply the first-visit
method and the every-visit method. For example, here is an episode:
This episode start from , so we can use it to evaluate
. However,
we can use it for more than just this: Hence, we are able to evaluate , , , and so on in
fact.
The so-called first-visit and every-visit are two different
strategies for making specific estimates. The difference between the two
is that they treat visits that take the same action in the same state
differently.
first-visit
If the agent returns to the state it was in before and takes the
action it took before in an episode, then we only use the first visit
for estimation. In this instance, there are two sub-episodes that both
start in state and take action
: In the first-visit method, we choose the longest sub-episode
for estimation, that is, for , only is
considered.
every-visit
In the every-visit method, if the agent returns to a previous state
and takes an action previously taken in an episode, we consider the
sub-episodes starting from these two points at the same time for
estimation. For example, we can take the average.
Update value estimate more efficiently (Generalized
policy iteration, GPI)
Generalized policy iteration refers to the general idea or
framework of switching between policy-evaluation and policy-improvement
processes. Many model-based and model-free RL algorithms fall into this
framework.
For MC exploring starts, a choice is using the returns of a single
episode to approximate the action value. In this way, we can improve the
policy episode-by-episode.
MC exploring starts
ε-greedy method:
The algorithms introduced in the previous article are all
deterministic, which means that when we apply first-visit / every-visit,
we can only take exploring starting due to we don’t know whether there
will be episodes starting from other states and actions passing through
this state and this action according to the policy. We have to use this
state and this state as the starting point of some episodes to ensure
that at least this point and this state are visited at least once.
This problem can be solved by soft policy, which is stochastic. The
policy obtained by the ε-greedy method is a soft policy method. It means
that for any state, every action in it has a chance to be chosen. where
and is the number
of actions for
It is easy to know that just embed into the MC-based
RL algorithms so that turn them into ε-greedy method. For ε-greedy
method, it is recommended to take every-visit.
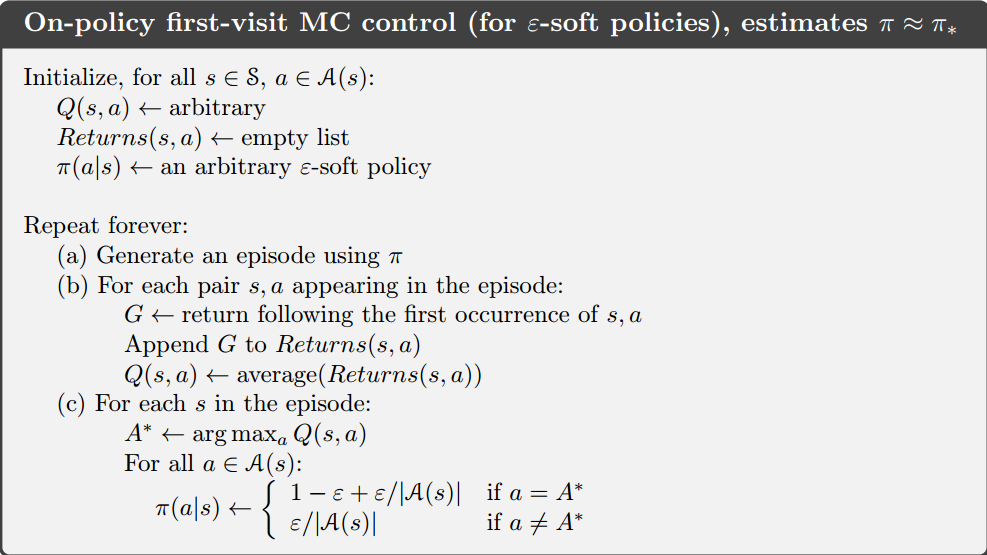
Here is a first-visit MC algorithm with the ε-greedy method,
What should be emphasized is can not be too large. Because
the optimal policy
directly obtained from the Bellman optimality equation should be greedy,
should be set to a
smaller value. In the design of the algorithm, can be set to a relatively
large value at the beginning and gradually decrease as the iteration
proceeds.
epsilon greedy algorithm
MC learning algorithms are not practical due to we need to calculate
for every state and episode, where is the episode length. should be adequately large, otherwise
the algorithm will be myopic and will fall into a local optimal solution
if the initial policy is not good enough. However, a too large will lead to a rapid increase in the
amount of computation.
Fortunately, temporal-difference learning algorithms can avoid this
problem.
Exploitation & Exploration, EE
WHY USE ε-GREEDY? Balance between exploration and exploitation:
When , it becomes
greedy, less exploitation but more exploration
When , it becomes
a uniform distribution, more exploration but less exploitation
The convergence of some stochastic approximation algorithms is
guaranteed by the Dvoretzky convergence theorem, including Robbins-Monro
algorithm. Furthermore, an extension of the it can prove the convergence
of Q-learning and TD learning.
SGD is a kind of Robbins-Monro algorithm, so its convergence can also
be proved using the Dvoretzky convergence theorem.
The Robbins-Monro algorithm that can solve is where is a noisy
observation of and is the noisy in k-th observation:
Robbins-Monro algorithm converges when the following conditions are
met: Robbins-Monro theorem is a special case of Dvoretzky
convergence theorem nearly: By the way, although the finite norm of means that , in actual
programming, the is
often not set to , but a very
small positive number is used as . This allows future
experience to play a relatively large role, rather than a extremely
negligible one.
Supposed we aim to solve the following optimization problem: where is a random
variable or random vector.
There are many algorithms based on the Robbins-Monro algorithm, such
as
Method 1: gradient descent, GD
Method 2: batch gradient descent, BGD
use MC method, Despite BGD no longer requires an exact mathematical
expectation but instead uses samples to estimate the mathematical
expectation, it requires many samples in each iteration for each .
Method 3: stochastic gradient descent, SGD As we can see, SGD = BGD with
Through Robbins-Monro algorithm, we know:
Method 4: mini-batch gradient descent, MBGD
SGD
temporal-difference learning
# Q-learning, the Bellman expectation equation
# on-policy, off-policy In the end, le u’s summarize the general form and properties
of the TD learning algorithms.
state value estimate with TD:
One of the simplest temporal-difference learning algorithm is to use
the Robbins-Monro algorithm to iterate the Bellman equation which aims
to estimate the state values of a given policy by iteration,
This formula can be annotated as where and is called the TD target.
Moreover, the TD error is
defined as
.
We can infer from this formula that This is the reason why we call as the target. Furthermore, TD
error reflects the
deficiency between and .
when . The larger the
, the greater the
difference between and .
Considering the framework of the Robbins-Monro algorithm, let , and , then and where is the
sample of which means the
next state.
From the above discussion, we can find the following points:
is the Bellman
equation.
is another form
of the Bellman equation because of . Therefore,
is sometimes called
the Bellman expectation equation, a magnitude tool to design and analyze
the temporal-difference algorithm.
is our
temporal-difference algorithm, which is based on the Robbins-Monro
algorithm. By combining and with the Robbins-Monro
algorithm, we can know that is actually solving the
Bellman equation by iteration.
By the temporal-difference method, we are no longer have to
calculate
for every state and episode compared to the MC learning algorithm.
Conversely, we only need to update the state value once when traversing
each state on a episode.
SARSA algorithm:
Currently, our TD algorithm can only calculate state values. To
perform policy improvement, we need to perform policy evaluation, which
in turn requires calculating action values. Sarsa
(state-action-reward-state-action, SARSA), an algorithm that can
directly estimate action values, can help us find the optimal
policies.
Suppose we have some experience ,
we can use the following Sarsa algorithm to find optimal policies with
the ε-greedy method and generalized policy iteration (GPI):
policy evaluation and update
where is an
estimate of and
is the learning
rate depending on .
It is definite that Sarsa just replaces the state value in the
previous algorithm with the action value. As a result, Sarsa is an
action-value version of TD algorithm. Just like the previous algorithm
solves the Bellman expectation equation
, Sarsa also solves an action value version of the Bellman
expectation equation.
Actually,
is another expression of the Bellman expectation equation in terms of
action values.
policy improvement with the ε-greedy method
Writing the above steps as pseudocode, the result is as follows.
Sarsa
Compared to the MC learning, Bias–variance tradeoff !
modification on Sarsa:
To modify Sarsa, here are two ways:
Expected Sarsa
we have then modify
update progress, Compared to Sarsa, the TD target
is changed to .
By this modification, the algorithm needs more computation when
updating .
Nevertheless, it is beneficial in the sense that it reduces the
estimation variances because it reduces the number of random variables
in Sarsa from to
.
Similarly, the expected Sarsa also solves another expression of
the Bellman equation:
-step
Sarsa
-step Sarsa is a synthesis of
Sarsa and MC method.
let actually but we only sample for
when calculating.
It is easy to know that is considered in Sarsa learning
and is considered in
Monte Carlo learning. The innovation in -step Sarsa is that it generalizes in Sarsa learning and in Monte Carlo learning to
by modify update progress as -step Sarsa needs
experience .
Evidently,
If is small, its performance
is close to Sarsa learning and hence has a relatively large bias due to
the initial guess policy and relatively low variance. Notably, -step Sarsa (basic) Sarsa algorithm.
If is large, its performance
is close to MC learning and hence has a large variance but a small bias.
Notably, -step Sarsa (basic) MC algorithm.
Q-learning algorithm:
As an off-policy algorithm, Q-learning does not need to switch back
and forth between policy evaluation and policy improvement due to it has
the ability to calculate the action value directly.
Replacing
in Sarsa learning with
gives us a Q-learning algorithm:
The following is the Bellman optimality equation expressed in
terms of action values what Q-learning aims to solve: the proof can be found in the reference mentioned at the
beginning of this article.
Now we can introduce the concepts of on-policy learning and
off-policy learning. Q-learning can be realized by both two ways.
First, we define two basic concepts:
behavior policy: a method used to generate experience samples
target policy: a method constantly updated toward an optimal
policy
Next,
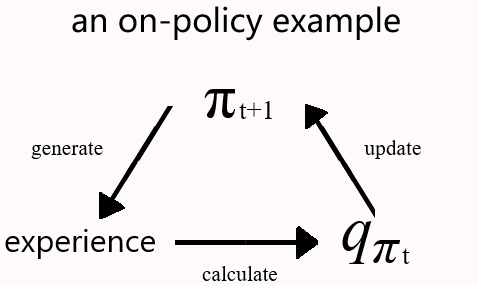
on-policy: When the behavior policy is the same
as the target policy, such kind of learning is called on-policy.
on-policy
off-policy: When the behavior policy and the
target policy are allowed to be different, the learning is called
off-policy. The algorithms can also update back and forth between
multiple episodes every time when applying the off-policy. Off-policy
algorithms can utilize data more efficiently by sampling without
replacement.
An off-policy algorithm can be implemented in an on-policy manner
(just set the behavior policy to the target policy), but not vice
versa.
One of the most significantly advantages of off-policy learning is
that algorithms are able to search for a optimal policies based on on
the experience samples generated by any other policies. As an important
special case, the behavior policy can be selected to be exploratory. Foe
example, if we would like to estimate the action values of all
state-action pairs, we can use a exploratory policy(e.g. ) to generate episodes visiting every state-action pair
sufficiently many times.
Pseudocode of Q-learning with on-policy:
on-policy Q-learning
Pseudocode of Q-learning with off-policy:
off-policy Q-learning
Off-policy is a very important property, which makes it easy to
combine neural networks with Q-learning in deep Q-learning.
However, when applying the off-policy method, consider whether
importance sampling is needed due to behavior policy and target policy
may be different. It should be pointed out that some papers indicate
that for Q-learning, DQN and DDPG do not need to perform importance
sampling, and doing so will not significantly improve the effect of the
algorithm.
All TD algorithms here can be expressed in a unified expression:
where is the TD
target. What algorithms aim to solve is that More specifically,
value approximation methods
# deep Q-network, DQN
function representation:
In the previous algorithm, although we gave some methods to calculate
or , we need to save the values of all
states . The structure of
saved data is logically a table, namely: It is called the tabular representation method and the
space complexity is . This
results in relatively large storage space requires overhead.
A natural idea to solve the problem is that we do not store all the
values, but approximate these values with a function . This method is called function
representation, and the value-based algorithm that applies
this method is called value approximation algorithm. For example, we can use a linear function to approximate.
function approximation
The function representation has the following advantages
obviously:
Storage: Just need to store a little bit of parameters for instead of all values.
Generalization: The algorithms are allowed to have stronger
generalization ability. In the tabular representation method, each
update only updates one value, and the other values remain unchanged;
while in the value approximation method, each update aims to update the
parameters of , which will also
affect the approximation of other values.
Sarsa with function
approximationQ-learning with function
approximation
The current mainstream value approximation method is to let be several neural networks. Q-learning
with neural networks is called
deep Q-network or deep Q-learning, abbreviated as DQN. DQN, one of the
earliest and most successful algorithms that introduce deep neural
networks into reinforcement learning, was published in the paper Playing
atari with deep reinforcement learning on 19 Dec 2013.
Next, this article will summarize the essence of this paper to
explain the principles of DQN.
DQN from the paper:
What the Q-learning aims to solve is a Bellman optimality equation:
Using the Bellman equation as an iterative update to maximize
the expected value of : In practice, this basic approach is totally impractical,
because the action-value function is estimated separately for each
sequence, without any generalization. Instead, it is common to use a
function approximator to estimate
the action-value function, .
Let , then a
DQN can be trained by minimizing a sequence of loss functions that
changes at each iteration ,
Tip: Squared loss
Differentiating the loss function with respect to the weights we
arrive at the following gradient, Rather than computing the full expectations in the above
gradient, it is often computationally expedient to optimize the loss
function by stochastic gradient descent. Then we can use gradient
descent for optimization.
A trick here is that the parameters from the previous iteration
are held
fixed when optimizing the loss function . In
other words, in should be equal to in theory, but we
treat it as a constant, so that the loss and its gradient are just
functions of
in . This
makes it easy to use SGD for optimization.
To do that, we can introduce two networks. One is a main network
representing and the
other is a target network representing . The
main network updates at each timesteps,
while the target network only assigns the value of to at some
timesteps, and keeps unchanged at
other timesteps.
Another trick is a mechanism called experience replay. It
means that after we have collected some experience samples, we do not
use these samples in the toder they were collected. Instead we store
them in a set, called replay buffer .
Every time we train the neural network, we can draw a mini-batch of
random samples from the replay buffer.
Why is experience play neccessary in DQN? The reason is that the
distribution of the state-action pair is assumed to be uniform due to we
have no prior knowledge of the distribution in the model-free condition,
where and . However, the
samples are not uniformly collected because they are generated
consequently by certain policies. Experience play is able to break the
correlation between consequent samples by drawing samples uniformly from
the replay buffer.
It should be noted that experience play is not necessary in
algorithms based on tabular representation, because tabular
representation does not involve the distribution of . In contrast, value approximation
algorithms based on function representation involve mathematical
expectation when optimizing the loss function,and therefore involve the distribution of , so experience play is
necessary.
Here is the on-policy version of pseudocode from the paper: Here is the off-policy version of pseudocode provided by Dr.
Zhao, where the gradient descent in the above derivation is omitted by
encapsulating it within the black box of a neural network:
DQN
where and
.
DQN only requires very little data to achieve the same effect
compared to Q-learning.
This chapter only records the most basic theoretical framework.
Different policy gradient algorithms have different detailed
implementations.
Previously, policies have been represented by tables, based on values
tables (action values). Now, we can directly access or change a value in the table.
Here, policies can be represented by parameterized functions , where is a
parameter vector. The function we choose is usually a neural network.
Advantage: When the state space is large, the tabular representation
will be of low efficiency in terms or storage and generalization.
Derivation of the gradients in the discounted
case:
In the policy gradient optimization problem, there are two equivalent
objective functions / metrics:
,
where
Limits form:
If the distribution is
independent of the policy , how
to select (which makes it easier
for us to calculate the gradient)?
One basic case is to treat all the states equally import. Select
.
Another basic case is that we are only interested in a specific state
. For example, the episodes in
some tasks always start from some state . Then, we only care about the
long-term return starting from .
In this case, , , where but .
If the distribution is
dependent of the policy ?
A common way to select as
, which is the stationary
distribution under . In theory,
.
We can learn from this formula that depends on .
where ,
and
Limits form: ,
stationary ergodic process, theory of stochastic
processes is needed when proved this formula.
When (for the
discounted case), we can prove that We are supposed to maximize or . Specifically, or
.
Summary of the results about the gradients: furthermore,
where
is when distribution does not depend on policy .
is
the probability of transitioning from to using exactly steps under policy .
is the discounted total probability of transitioning from to under policy .
is the state distribution, .
in fact. For undiscounted case, here is ''; while for discounted case, here is
''.
We can summarize the above formulas with the following formula: where is a
distribution of weights of the states.
The above is one form of the theoretical value of the gradient. But
in actual optimization, we often use another form written as
expectation, because it is more convenient to use the Monte Carlo method
to approximate the exact value with samples: To prove this equation, we can refer to the operation in
calculating the maximum likelihood estimate, first take the logarithm of
, and
then calculate the gradient. Finally, we can get the following formula:
Substituting this formula into the expression for
in the previous article: Similarly, Here, the approximation is more accurate when is closer to .
Derivation of the gradients in the undiscounted
case:
Since the undiscounted sum of the rewards, ,
may diverge, redefine state and action values:
Then rewrite as matrix-vector form, This equation is called the Poisson equation, which is similar
to the Bellman equation.
By the Poisson equation, we know that Notably, the undetermined value is canceled and hence is unique
(while
is not unique). Therefore, we can calculate the gradient of in the
undiscounted case.
We can prove that
As we can see, in both discounted and undiscounted cases, when there
are s.t.
,
we can not calculate on
. To avoid it, we can
using softmax function to normalize the entries in a vector from . As a result,
where is
another function.
This is easy to archive for neural networks. Just input the logits
obtained from the output layer into the softmax functions. However,
since for all
, the parameterized policy is
stochastic and hence exploratory. Therefore, this method can not handle
the case of infinite actions. It can be solved by the actor-critic
methods.
REINFORCE (policy gradient with MC):
REINFORCE is the simplest policy gradient algorithm. Just combine
gradient ascent algorithm and Monte Carlo method. If is
obtained by Monte Carlo estimation, the algorithm is called REINFORCE or
Monte Carlo policy gradient, which is one of earliest and simplest
policy gradient algorithms. If is obtained by other
estimations, like TD, the algorithms are called actor-critic.
For REINFORCE, is the
behavior policy and also target policy, so REINFORCE is an on-policy
algorithm.
REINFORCE
In addition,
philosophy about beta_t
actor-critic methods
Methods that learn approximations to both policy and value functions
are often called actor-critic methods, where 'actor' is a reference to
the learned policy, and 'critic' refers to the learned value function,
usually a state-value function.
For example, in REINFORCE, Q actor-critic algorithm, QAC:
QAC is one of the simplest actor-critic algorithms. where is
estimated by Sarsa.
QAC is on-policy. Do not need to use techniques like ε-greedy method,
because QAC performs exploration due to the policy is stochastic ().
advantage actor-critic, A2C:
QAC is extended to obtain advantage actor-critic, Q2C. The core idea
is to introduce a baseline to reduce variance.
It is easy to prove that where the additional baseline is a scalar function of .
Hence If we let ,
then
is invariant
to
is not
invariant to
Specifically, ,
although is
invariant to , So we are supposed to select an optimal baseline to minimize .
In the algorithms of REINFORCE and QAC, there is no baseline. Or, we
can say , which is not
guaranteed to be a good baseline.
We can prove that the optimal baseline which can minimize is, , However, this baseline too complex to utilize.
Commonly, we select the suboptimal baseline So we call
as the advantage function, then Furthermore, the advantage function is approximated by the TD
error, This approximation is reasonable due to Benefit: Only one network in need to approximate rather than two networks for
and !!!!!!
A2C
A2C is on-policy. Do not need to use techniques like ε-greedy method,
because A2C performs exploration due to the policy is stochastic ().
advantage async actor-critic, A3C:
temporary omission
off-policy actor-critic:
The actor-critic algorithms introduced above are all on-policy due to
.
Therefore, is the
behavior policy and also target policy.
Note that the gradient expression contains mathematical expectation,
which means that we can convert the on-policy algorithm into an
off-policy algorithm through importance sampling techniques.
Suppose is the behavior
policy that generates experience samples, our aim is to use these
samples to update a target policy that can maximize the following
metric where is the
stationary distribution under policy .
We have this theorem, For example, we can convert on-policy A2C to off-policy A2C by
this theorem, Pseudocode of actor-critic with off-policy:
AC with off-policy
deterministic actor-critic, DPG:
By using deterministic policies in the policy in the policy gradient
methods, we are able to handle continuous action.
When we require the policy
to be a deterministic one , a
new policy gradient regarding
must be derived, where is a
distribution of the states and is the
action under the deterministic policy.
for average value where is the state distribution and
is the discounted total probability of transitioning from to under policy .
for average reward where is the
stationary distribution of the states under policy .
Algorithm description: In particular, the experience sample required by the critic is
,
where .
The generation of this experience sample involves two policies. The first
is the policy for generating at
, and the second is the policy
for generating at
. The first policy that
generates is the behavior
policy since at is used to interact with the environment. The second
policy must be because it is
the policy that the critic aims to evaluate. Hence, is the target policy. It should be
noted that is not
used to interact with the environment in the next time step. Hence,
is not the behavior policy.
Therefore, the critic is off-policy.
DPG
can be any exploratory
policy. It can also be a stochastic policy obtained by adding noise to
. In this case, is also the behavior policy and hence
this way is an on-policy implementation.
deep deterministic actor-critic, DDPG:
How to select the function to represent ?
DPG: Linear function, where is the feature vector.
{kind=link}