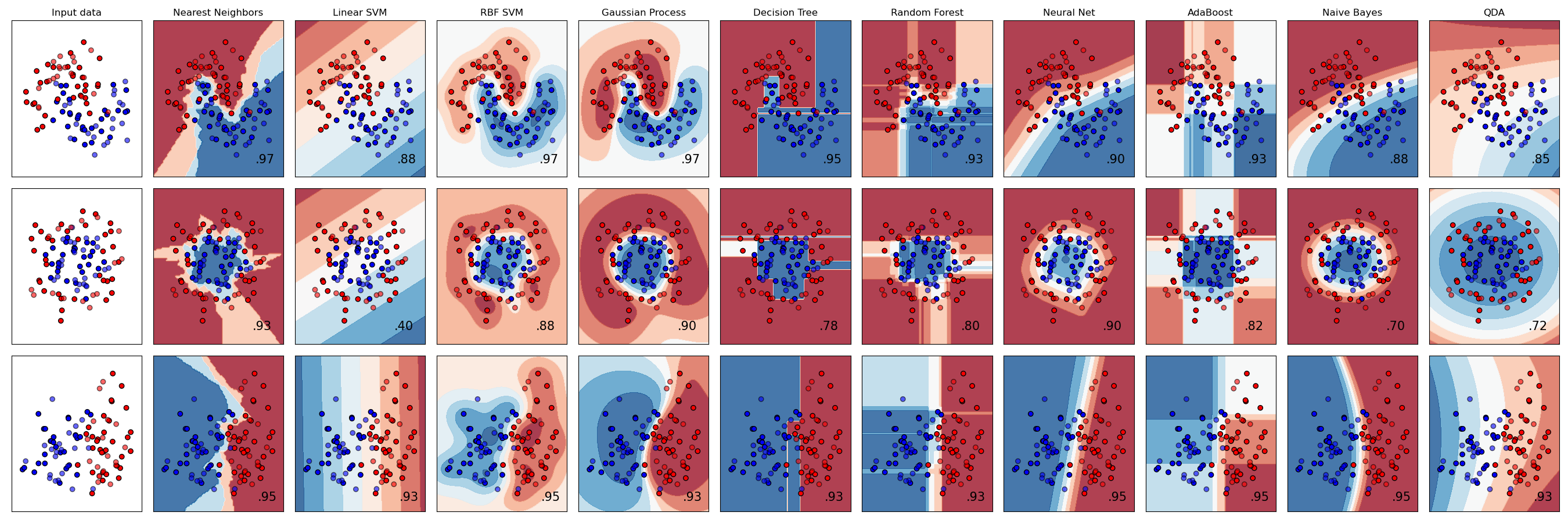
切换桌面渲染模式
文前提示:如果移动端访问时未显示侧栏,可点击左侧按钮以查看侧栏目录。
支持向量机的一些并不算深入的基本数理理论,包含SVM、SVR与LS-SVR。支持向量机具有非常强的数学与统计理论支撑,研究SVM的数理理论对加深对SVM的理解是大有裨益的。
在我们开始以前,我想谈谈关于我与统计学。作为西南大学数学与统计学院统计系的学生,在修完数学课程如实变函数论、近世代数与泛函分析后,学院相继为全体学生开设了最优化理论、统计计算、多元统计分析与回归分析等多门统计课程,唯独不统一在学院开设机器学习。优化理论与统计计算算法在机器学习中扮演了重要角色,譬如大名鼎鼎的拟牛顿法之代表BFGS算法、用于非凸优化问题的退火算法和遗传算法都有广泛的应用,但修习了这些理论却不开设后续课程实属遗憾,这些理论当然也就没有了用武之地,成了一纸空谈。通过参考多方资料,我在没有教师帮助下独立探索了一些机器学习理论,希望结合数学理论与数理统计学方法,加深对机器学习的理解。本文主题是记录一些我关于“SVM”的想法与感悟,由于才疏学浅,只能做到泛泛而谈,如有纰漏与谬误恳请与我联系。
个人认为,许多机器学习算法都或隐或明地蕴含了不少的数学与统计思想,如SVM的优化涉及最优化理论与统计计算算法(退火算法、遗传算法),核函数的提出源自Hilbert空间算子理论,正则化与
鹦鹉学舌也好,拾人牙慧也罢,普通学生,普通家庭,确实没有动力与能力独立开创、推广新的理论,这篇文档的意义可能是十年后再回首,说明本科时的我曾经有试图学习些什么过吧。
为方便表述,记
MSE:均方误差,
广义拉格朗日乘子法与KKT条件:用隐函数组定理是容易证明的,在任意一本数学分析与最优化理论教材都有证明过程;
如无特殊说明,本文用
1. SVM(SVC)
1.1. SVM概论
1.1.1. SVM的思想
SVM(支持向量机,Support Vector
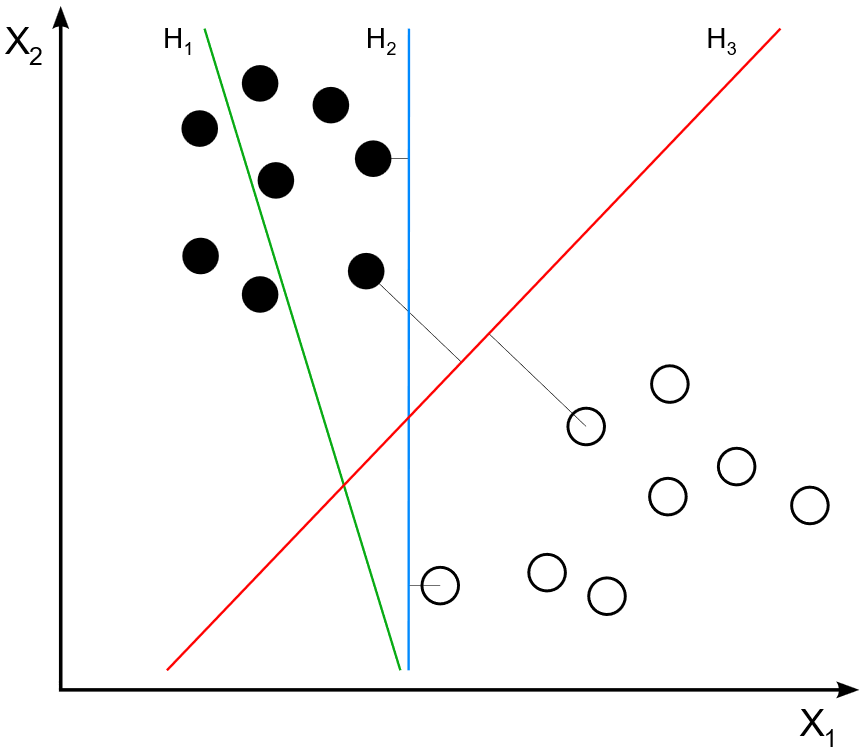
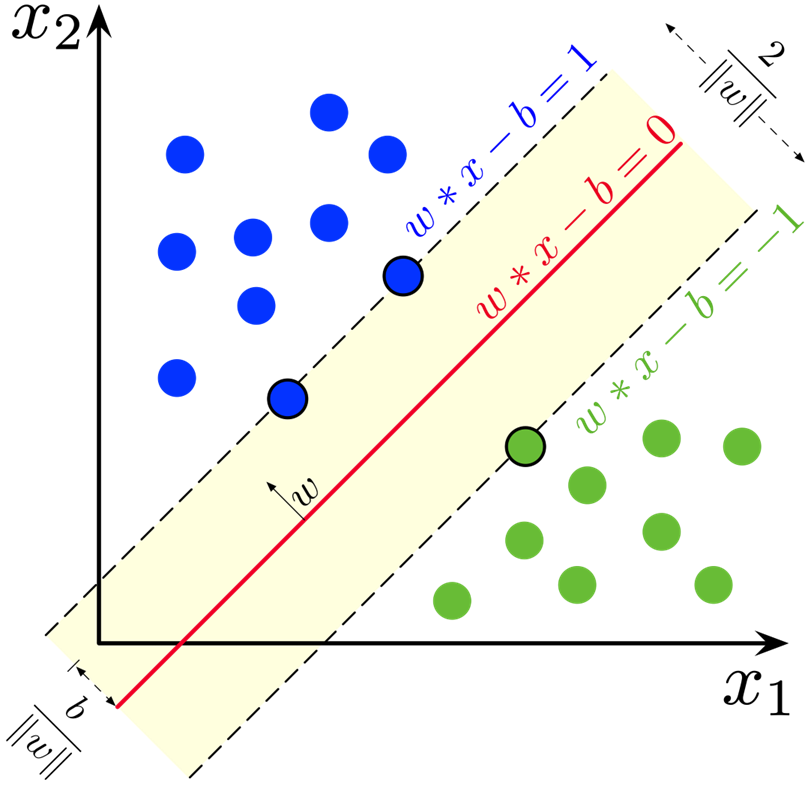
Machine)是一种有监督学习方法,属广义线性分类器家族,其目的是对数据进行二分类,既可以通过寻找一个当前样本空间的分割超平面进行线性分类,也可以通过核方法在更高维空间中寻求高维超平面进行非线性分类,并且可以被应用在回归分析。在我看来,SVM的想法是自然的,这与线性回归中OLS的思路如出一辙。如果说OLS的目的是获得使得RSS最小的估计,则二分类SVM的目的是获得某个超平面,使得其两边支持向量到超平面距离最大且相等。在高斯-马尔可定理条件成立情况设下,线性模型的OLS得到BLUE,误差在MSE意义下最小,对于良好的数据集大部分样本点都应该以较小的距离分布在拟合直线两侧;而SVM试图找出一个高维的超平面,使两类样本距离这个超平面最近的距离相等且最大,如下图所示。显然,三条一维直线中
但OLS与SVM并非高度一致,在信息利用上有明显的差异:OLS的预测利用了所有的样本(最小化RSS),而SVM只利用到了支持向量,非支持向量的任何改变都不会对结果产生丝毫影响。
1.1.2. SVM在应用中的的优缺点
SVM在小样本、非线性以及高维模式识别等方面有出色的表现,且容易结合其他方法进行推广应用,在文本、超文本分类与生物、医学及其他科学领域已经有了广泛的运用,一些浅层语义分析也基于SVM,样本量适中而特征数不算多时有很好的分类能力;
SVM的潜在问题包含,作为彻底的有监督学习、能利用的样本必需有完整的标记(决策树方法不需要),只适用于二分类任务,得到的模型参数难以得到现实意义的解释(业务上线性回归参数便有极强的可解释性,SVM通常不能做到),对缺失数据敏感。
同时,SVM的优化目标为一个二次凸优化,有良好的凸优化性质(优化算法一定收敛到唯一全局最优解),但这也使得超大样本量情况下SVM求解异常困难,使带有核方法的SVM理论实践复杂度不低于
与一些神经网络算法不同,SVM目前已有严格的数学与统计理论支持。SVM基于Vapnik
和 Chervonenkis提出的Vapnik-Chervonenkis
理论(下称VC理论)与结构风险最小原理,属于非概率二元线性分类器,并没有严格按照随机抽样的原则抽取样本,无法确定抽样误差,因此大数律与中心极限定理等极限理论也并不适用;同时这令他并没有过分在意样本空间的维数,以至于为了达到非线性分类的目的可以多次升维,而且折中了精度(Accuracy)与学习能力的原理令SVM有较好的泛化能力,但这需要对SVM进行一些改进以达到更好的效果,比如软间隔的方法。
此外,由于非线性核的SVM理论上时间复杂度不低于
1.2. 支持向量
假设我们需要找到的分割超平面为
根据空间解析几何理论,样本空间中任意一点此 时 此 时
令使得间 隔
1.3. 优化问题
SVM中一般考虑对直观下约束优化问题的拉格朗日对偶问题优化,相对原优化目标效率更高,这里有一点需要解释,关于为什么我们考虑对偶问题:我们可以不从原问题的对偶问题出发考虑求解,例如线性核SVM的原始优化问题为下文的
大体上,我们的求解办法是通过优化方法计算出对偶问题的解(即
1.3.1. 支持向量与对偶问题
容易想到,一般分割超平面间隔越大,分类能力越强,因为越大的分割对误差有更大的容许,对噪声导致的数据波动有更高的忍耐,而不至于某样本稍稍偏离主体便被错误划分为另一类。
直观来看,为了找到这个最合适的超平面,我们需要解决一个如下的约束下最大化分隔稳 定 性 条 件
稳 定 性 条 件
原 问 题 可 行 性 对 偶 问 题 可 行 性 互 相 松 弛 条 件
注意到,
容易看出
值得一提的是,SVM之所以在高位模式识别领域具有优势,是因为面对维数诅咒SVM只利用了比较少的样本(只利用了支持向量)。通常对于高维数据,常用的方法有①
特征选择,如Lasso回归;② 直接降维,如PCA、MDS、LLE;③
正则化,以减轻高维样本空间带来的多重共线性等不良影响;④
增加样本量,深度学习便是沿着这个思路;在今天大数据的时代下,一个大型深度学习模型拥有上百亿个参数都不足为奇。
1.3.2. 参数
求参数的解我们仅用到了支持向量,因此在优化求拉格朗日乘子完成以后,我们需要的样本便只剩下支持向量了。
对于
对于
在通过算法求出
这一章节中所有需要预测的样本
注意此 时 此 时
1.4. 核方法
1.4.1. 核方法的思想
目前为止,我们的SVM算法只能求解线性分类问题,比如“且”问题、“并”问题与“非”问题,但“异或”这样的非线性分类问题并没有办法解决,从我们的思路与
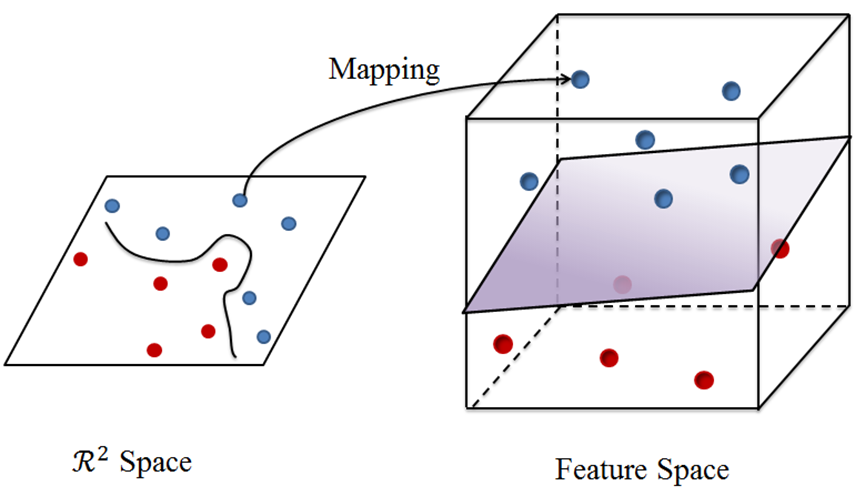
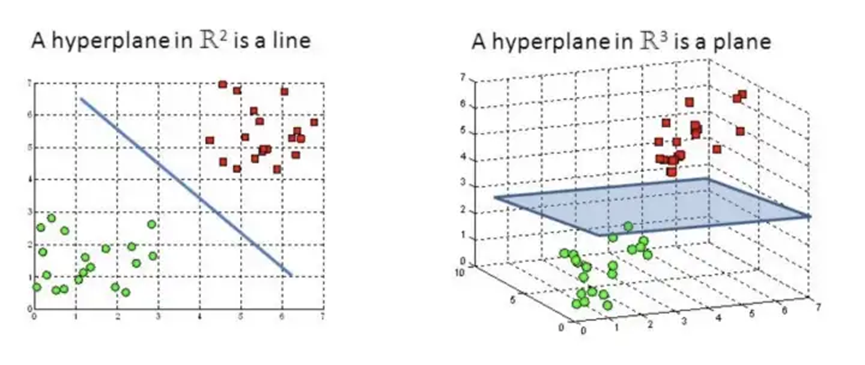
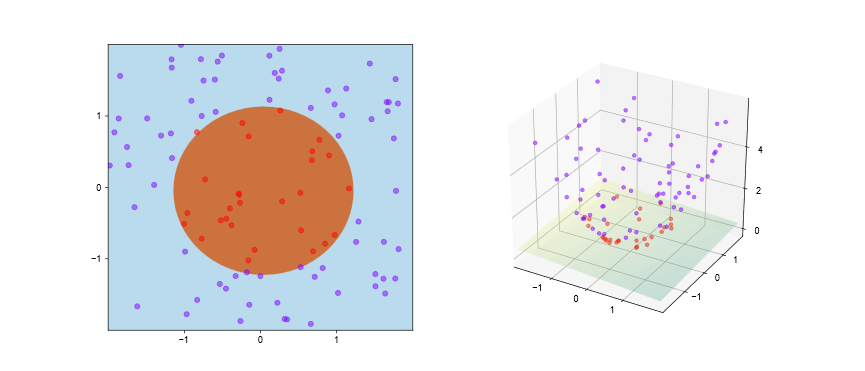
不过我们仍有解决办法让SVM有能力处理非线性分类问题:我们可以将样本空间映射到一个更高维的空间,使样本在这个更高维的空间可分,例如下图左部分的分类问题,当我们把二维的自变量空间升至
对于有限维的样本空间,即属性数或者将向量的分量数是有限的,则必存在一个高维空间使得样本线性可分,这是显而易见的,只不过可能在这一高维空间下的内积难以计算。
对于非线性分类问题,用
核函数的Mercer定理:二元对称实值函数
Mercer定理确保了这样一个核函数必定存在,但是否可行、如何寻找最佳核函数,同岭估计最佳岭值的确定一样目前没有普遍适用且最佳的方法,这是值得研究的问题。现在有一些综合多种常用核函数考量的技术,这借助了集成学习的算法。
1.4.2. 核方法的泛函分析理论支持
这一部分是纯粹理论的推导,如果不关心底层理论可以略过,毕竟这需要一定的数学基础;
希望这部分读者拥有数学及相关专业本科生或理工研究生以上的泛函分析水平,起码对泛函延拓定理要有所耳闻。
1.4.2.1. 核函数与Mercer定理
Mercer定理确保了只要一个对称函数对应的核矩阵半正定,那么他就能被当作核函数应用,这是核技巧的关键,是核技巧得以存在的理论支持。事实上,定义核函数等价于定义了一个RHKS(再生核的Hilbert空间)。
首先定义核函数,若二元实值可积函数
现在让我们把核矩阵定义推广至任意一个二元实值对称函数
离散形式的二元Mercer定理:设
离散形式的二元Mercer定理很容易推广到更一般的测度空间上,事实上Mercer定理是Hilbert-Schmidt定理的特殊情况,鉴于本文并不是泛函分析教程,不再赘述;证明Mercer定理可以考虑Mercer定理的条件满足Hilbert-Schmidt定理的条件,这需要几个引理与共鸣定理。
Mercer定理参考:https://johnthickstun.com/docs/mercer.pdf
[John Thickstun, MERCER’S THEOREM ]
Hilbert-Schmidt定理参考:https://core.ac.uk/download/pdf/82400668.pdf
[José L. Martínez-Morales, The Kernel Theorem of
Hilbert–Schmidt operators , 2003]
1.4.2.2. RKHS(再生核Hilbert空间)
我们知道
当我们把
1.4.3. 常见的核函数
理论上,如果知道了映射的选取,便能确定一个最佳核函数;但许多时候这并不容易做到,下列部分常用的核函数,在一些特定情况下能取得不错的效果。除线性核外,统称非线性核。
一些常见的核函数
函数形式
注解
线性核
即多项式核在
齐次多项式核
非齐次多项式核
径向基函数核,RBF核(高斯核)
为了参数化,可以令
拉普拉斯核
双曲正切Sigmoid核
除了上述核函数,还有字符串核函数、
核函数的一些运算性质,使得我们可以通过已有核函数构造获得更多新的核函数:
① 若
② 若
③ 若
既然核方法如此强大,为何我们不在逻辑斯蒂回归中也大量运用?这是因为SVM优化问题的拉格朗日对偶问题便于使用核方法,而逻辑斯蒂回归的损失函数交叉熵核化后难以优化求解,甚至不能确定凹凸性。
经验上看,用
(1) 如果
(2) 如果
(3) 如果
(4)
逻辑斯蒂回归与线性核SVM算法相似,但在样本量高达数十万时线性核SVM表现通常比逻辑斯蒂回归好。
1.5. 软间隔与正则化
软间隔与正则化都是对付过拟合的手段。
1.5.1. 软间隔
上文提到了一个问题:虽然我们可以通过核方法将样本映射至高维使得样本在高维空间线性可分,但我们还不能确定该选用何种核函数较为合适,也不能确定究竟要将样本映射到多高维的空间能使得其线性可分。同时,目前我们的SVM方法过于严格,因为我们要求分割超平面必须考虑所有的样本点来寻找支持向量。这可能在实际情况下并不太实用,因为非常容易造成过拟合的问题,让SVM学习到一些本不应该学习的、仅出现在特定样本的特点。
通过允许一些SMV在部分样本上“犯错”,即让部分样本突破限制而使得其满足
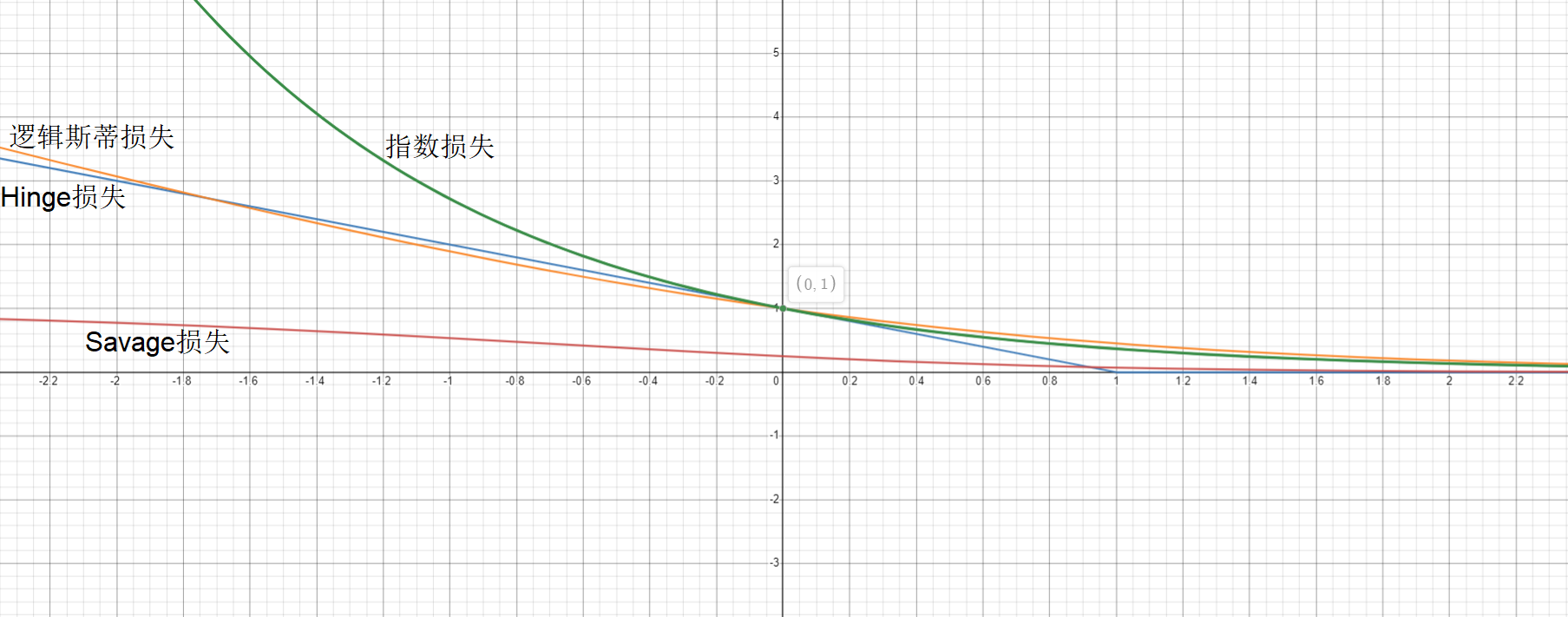
1.5.1.1. 替代损失
为了达到上述目的,我们对
但这个函数解析性质较差,不方便推导,也不易优化求解,常用其他函数替代,称为替代损失,为了有良好的优化性质,一般都期望替代损失是凸函数;SVM需要的替代损失还要求在
一些的替代损失
函数形式
注解
Hinge损失(铰链损失)
Hinge损失的应用非常常见,但得到的解较为稀疏;有时取其平方
指数损失
逻辑斯蒂损失(lnistic损失,对数几率损失)
对异常值不敏感
Savage损失
上述替代损失除Savage损失已于2004年被证明与经验风险最小化问题是一致的,即通过求解替代损失函数仍是原问题(
由于Hinge损失在
对
可以认为式 式
一般来说,
从结果上看,
1.5.1.2. 松弛变量与软间隔SVM
这里考虑应用Hinge损失,引入松弛变量
稳 定 性 条 件 稳 定 性 条 件 稳 定 性 条 件 原 问 题 可 行 性 对 偶 问 题 可 行 性 互 相 松 弛 条 件
软间隔具有非常广泛的应用,能有效降低过拟合带来的影响,使得SVM不会学习太多特定样本的特征。实际应用中大多数两类样本的分布很可能是糅合的,如果不允许SVM在特定样本上稍稍“犯错”会使得把这一特定样本的误差、噪声、极端分布等因素通通不加筛选地学习,这大大降低了模型泛化的能力。
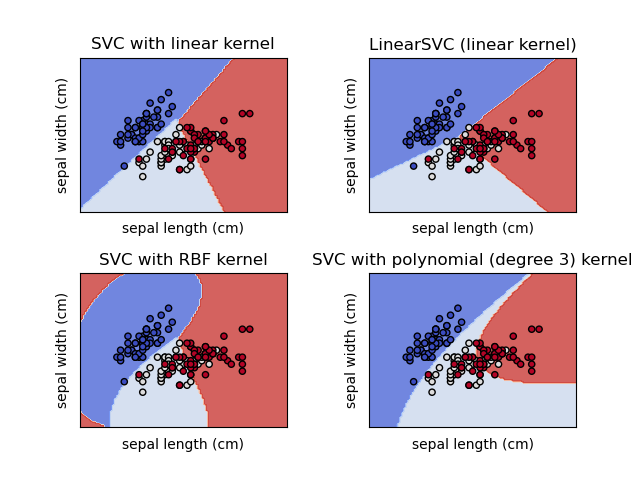
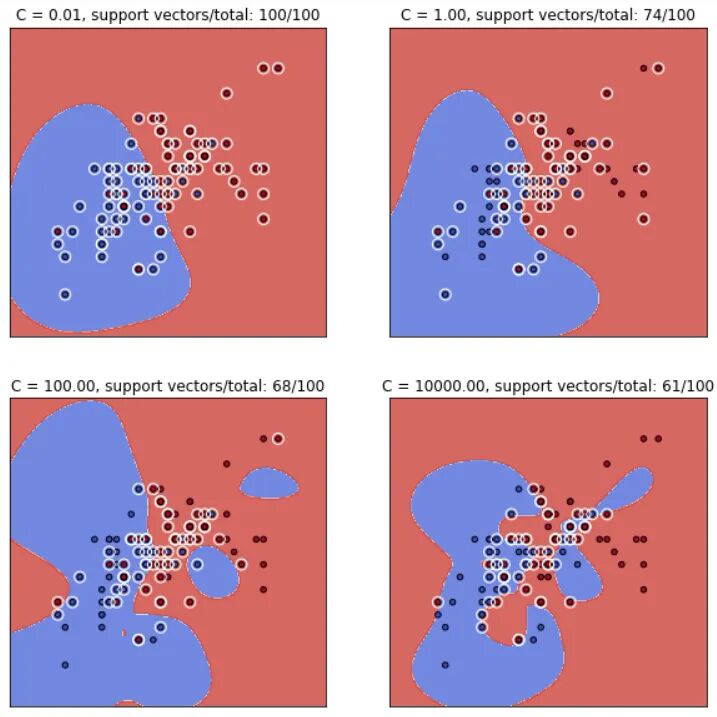
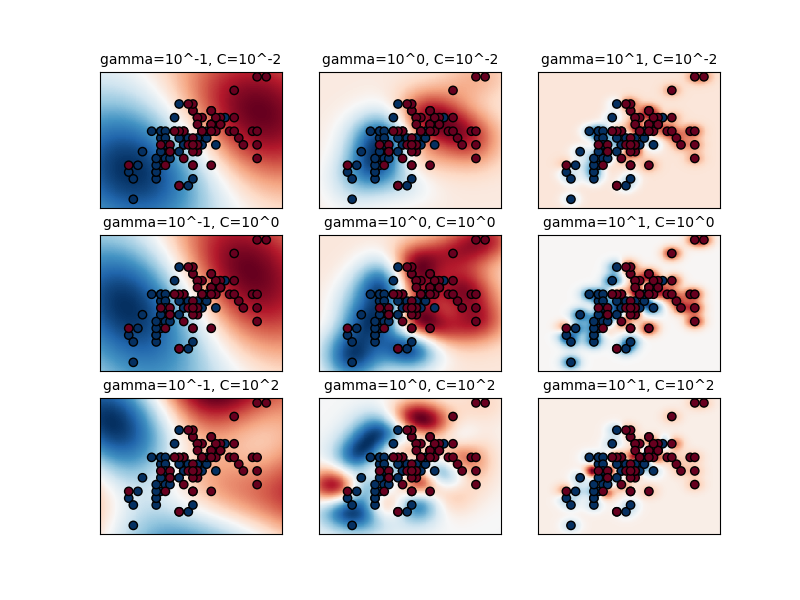
径向基函数的支持向量机分类效果关于
可以看出,随着 。
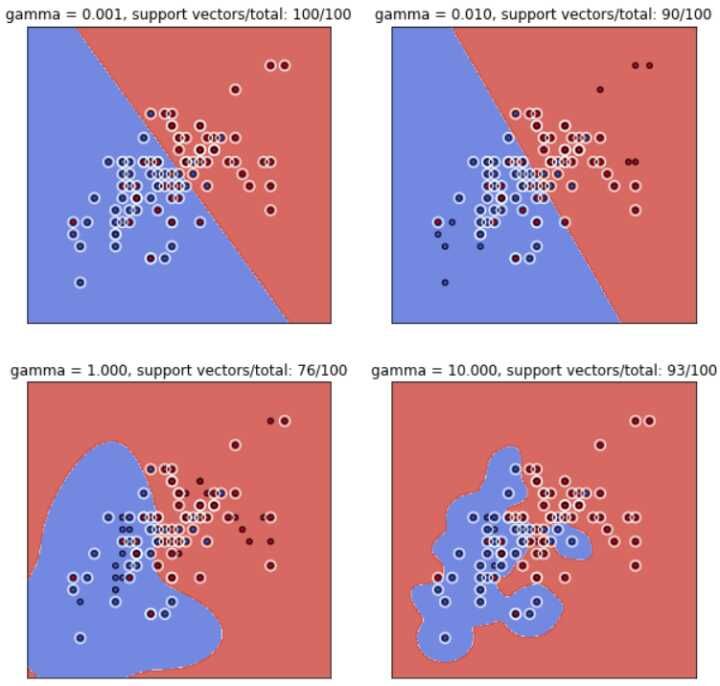
径向基函数的支持向量机分类效果关于
可以看出,随着 。
综上所述,可以得出一个推论:单单凭借支持向量的个数是不能判断RBF核SVM是否过拟合或欠拟合的。
直观体现如下,阴影代表支持向量影响范围:
1.5.2. 更为一般的正则化的观点
首先我们提出更一般的优化目标
结构风险
经验风险
式
VC理论介绍:https://www.cs.cmu.edu/~epxing/Class/10701/slides/lecture16-VC.pdf
关于VC理论更多的信息可以Google “Vladimir Vapnik”.
VC理论经典文献参考:http://www.mit.edu/~6.454/www_spring_2001/emin/slt.pdf
[Vladimir N. Vapnik, An Overview of Statistical Learning
Theory , 1998, IEEE]
1.6. SVM多分类问题
SVM作为二分类分类器被提出,要进行多分类可以考虑一对一One Versus
One利用得分或DAF(有向无环图)输出结果、一对多One Versus the
Rest组合出结果;现在也有一些“直接”多分类的SVM变种方法,目前这些方法需要的算力很大,花费的时间仅在小样本下可接受。
Multiclass SVM aims to assign labels to instances by using support
vector machines, where the labels are drawn from a finite set of several
elements.
The dominant approach for doing so is to reduce the single multiclass
problem into multiple binary
classification problems. Common methods for such reduction
include:
Building binary classifiers that distinguish between one of the
labels and the rest (one-versus-all ) or between every pair of
classes (one-versus-one ). Classification of new instances for
the one-versus-all case is done by a winner-takes-all strategy, in which
the classifier with the highest-output function assigns the class (it is
important that the output functions be calibrated to produce comparable
scores). For the one-versus-one approach, classification is done by a
max-wins voting strategy, in which every classifier assigns the instance
to one of the two classes, then the vote for the assigned class is
increased by one vote, and finally the class with the most votes
determines the instance classification.
Directed
acyclic graph SVM (DAGSVM)Error-correcting
output codes
Crammer and Singer proposed a multiclass SVM method which casts the
multiclass
classification problem into a single optimization problem, rather
than decomposing it into multiple binary classification problems. See
also Lee, Lin and Wahba and Van den Burg and Groenen.
2. SVR
2.1. SVR概论
2.1.1. SVR的思想
此前我们讨论的SVM是从二分类问题出发的,即所谓的SVC,Support Vector
Classification,支持向量分类。这里我们着重探讨SVR,Support Vector
Regression,即支持向量回归,是将SVM技术应用在回归分析的一种方法,是一种有监督学习。
1996年,Vladimir N. Vapnik、Harris Drucker、Christopher JC
Burges、Linda Kaufman 和 Alexander J.
Smola提出了将SVM应用于回归的方法。
种种经典的(广义)线性回归模型,包括岭回归、Lasso回归、Elastic
Net回归与逻辑斯蒂回归等等,都有一个共同的特点:当且仅当预测值与真实值完全相同时,损失才为
在SVR中,最佳拟合超平面就是容许至多偏差
2.1.2. SVR在应用中的优缺点
通过控制
而且SVR对数据缺失较为敏感,不能很好的利用邻近数据对缺失数据的趋势进行良好的拟合。
2.2. 优化问题
2.2.1. 对偶问题
对于SVR,根据前文的分析,我们从软间隔SVM的优化目稳 定 性 条 件 原 问 题 可 行 性 对 偶 问 题 可 行 性 互 相 松 弛 条 件
2.2.2. 参数
同样地这里我们只用到了一部分样本,而不是全部样本,这与线性回归不同。
在通过优化方法解得全部的拉格朗日乘子后,我们首先由
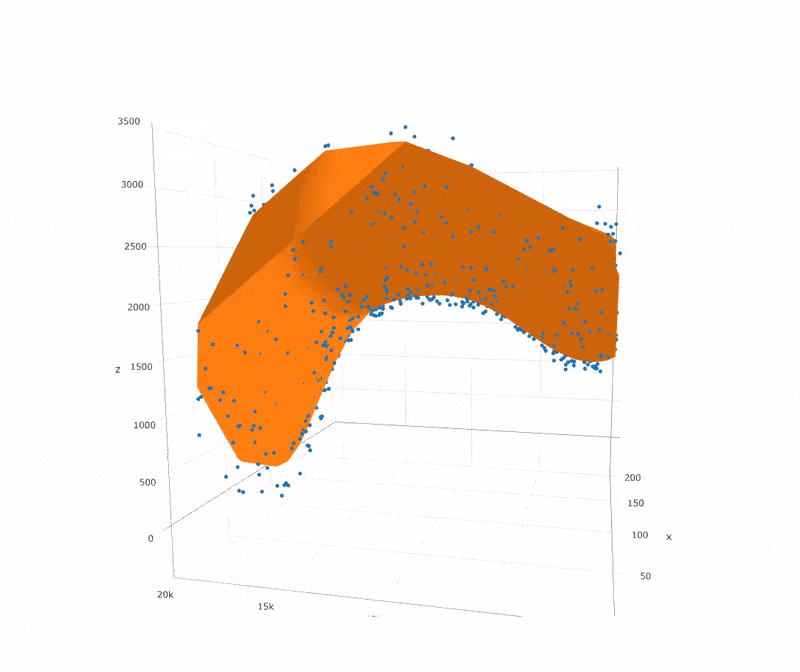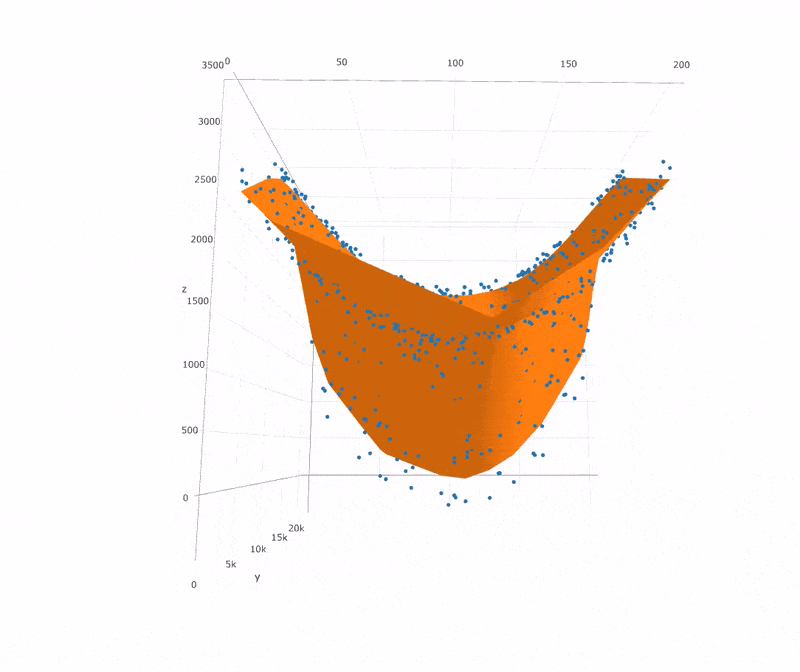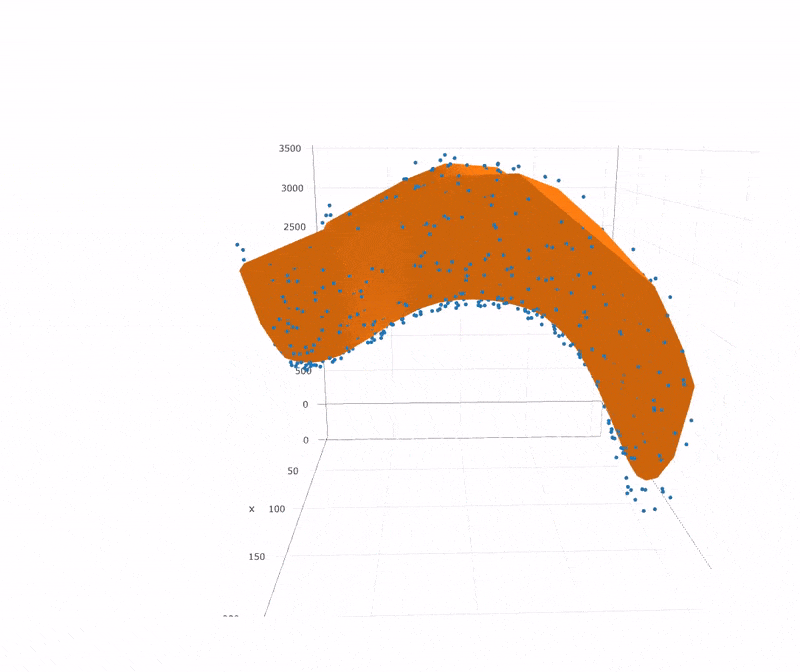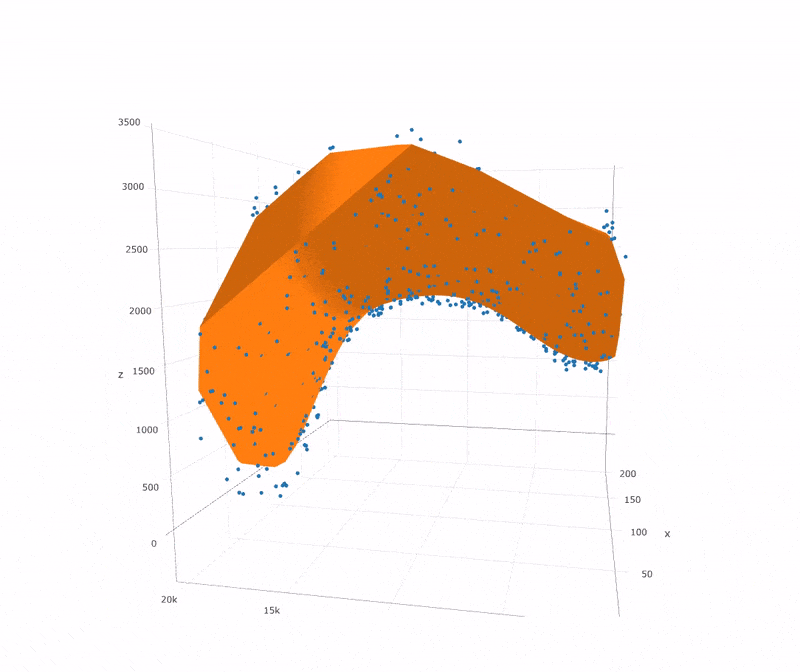
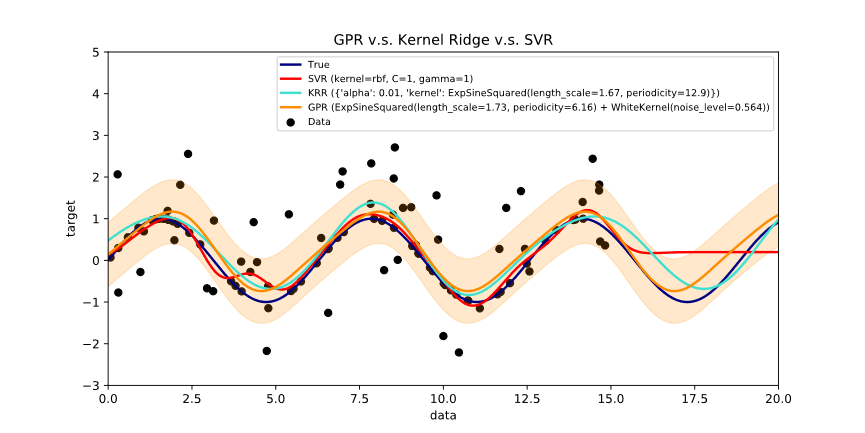
上图中Kernel Ridge
Regression便是我们再熟悉不过的核化岭估计,在我的另一篇
可以看出,如果样本点有一段存在缺失,那么SVR的效果并不算太好。
3. 核方法广泛的运用场景
在SVM中我们通过核方法使得我们可以处理非线性可分的场景,那么我们可以把这个方法推广至其他应用场景,比如岭估计吗?
答案是可以的,首先我们需要一个被称为表示定理的定理。表示定理于2002年首次被证明,考虑利用Mercer定理构造,鉴于过程过于繁琐且复杂,证明略过。
表示定理:设
表示定理虽然证明需要一定的理论基础,但他揭示了一个简单且强大的结论:只要正则化项单调递增,那么任何符合形式
4. LS-SVM与LS-SVR
4.1. 从SVR出发推导LS-SVM
LS-SVM(最小二乘支持向量机)于1999年由Sukyens提出,与之对应的是LS-SVR(最小二乘支持向量回归),其实这就是带核的岭回归 。较之SVR,LS-SVR用
4.2. 从岭回归出发推导LS-SVM
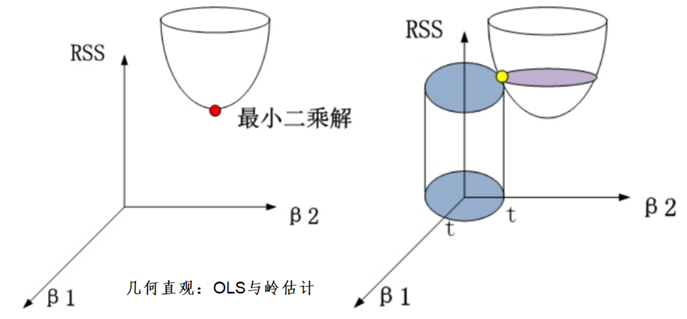
在此之前,我们先简单介绍一下岭回归——一种最小二乘法的推广。对于普通岭回归,或者讲带有线性核的岭回归模型为
有 偏 性 :
目前为止,我们简单介绍了岭回归。
欲在岭估计中应用核技巧,首先对
5. SMO算法的简单解释
SMO(Sequential Minimal
Optimization),一般译作顺序最小化(优化)算法。
SMO算法每次选取一对拉格朗日乘子除 去 与 对 应 的 下 标
选取一个拉格朗日乘子
通过
转回步骤1.,直到收敛.
之所以令
经典文献参考:https://web.iitd.ac.in/~sumeet/tr-98-14.pdf
[John C. Platt, Sequential Minimal Optimization: A Fast
Algorithm for Training Support Vector Machines , 1998]
6.
R的e1071包与Python的sklearn库中的SVC&SVR
6.1. R(e1071 & tidymodel)
R - e1071官方文档:https://cran.r-project.org/web/packages/e1071/e1071.pdf
似乎'tidymodel'更方便?
6.2. Python(sklearn)
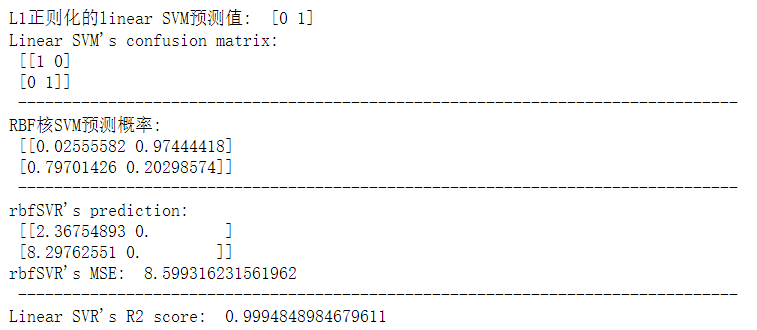
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 ''' SVC(概率/非概率),参数: C:C值,取值在0~1之间,用于软间隔的惩罚系数(软间隔影响权重),C值越大越严格,松弛变量越接近0,分类准确率高,可能造成过拟合(=1) kernel:选择核函数(="rbf"),可选的有"rbf"、"linear"、"poly"即多项式核、用degree控制阶(=3),"sigmoid" gamma:核函数系数,"rbf"、"poly"、"sigmoid"的参数(="auto",即特征数倒数) coef0:核函数的常系数,"poly"、"sigmoid"的参数 tol:终止准则的精度(=1e-3) probability:是否输出概率(=False) decision_function_shape:分类方式,可选"ovo","ovr" class_weight:给每个类分别设置惩罚系数,不给就是1,等价于全设置为C(=None) random_state --------------------------------------------------- shrinking:是否只考虑支持向量(=True),理论上选择False不影响结果,但会使程序变慢 verbose:是否详细输出(=False) --------------------------------------------------- 方法: .score(X, y) .predict(X) .predict_proba(X) --------------------------------------------------- 成员变量: .decision_function # 测试样本到超平面的距离 .n_support_ .support_ # 支持向量的索引 .support_vectors_ .coef_ .intercept_ *************************************************** 特别地,LinearSVC还有一些可调整的参数, penalty:超平面w”长度“的约束方式,"l1"、"l2",选择"l1"得到的解稀疏,即非0分量尽可能少(="l2") loss:选择软间隔的损失函数,即”允许SVM犯错次数“计数器,"hinge"或"squared_hinge",hinge loss(z)=max(0, 1-z)(="squared_hinge") dual:对偶问题,当样本数远大于特征数时,或许应该选择False?(=True) multi_class:"ovr"或"crammer_singe"(="ovr") max_iter:最大迭代次数(=1000) ''' X = [[1 , 2.5 , 3 ], [4.5 , 5 , 5.5 ], [7 , 8 , 9.5 ], [10.5 , 11 , 12 ]] y_class = [0 , 0 , 1 , 1 ] X_val = [[0 , 1 , 2.5 ], [13 , 14.5 , 16 ]] y_class_val = [0 , 1 ] from sklearn.svm import SVC, LinearSVCfrom sklearn.metrics import confusion_matrixlinearSVM = LinearSVC(penalty="l1" , dual=False , max_iter=5000 ) linearSVM.fit(X, y_class) rbfSVM = SVC(C=0.8 , kernel="rbf" , probability=True ) rbfSVM.fit(X, y_class) pre = linearSVM.predict(X_val) CM_linearSVM = confusion_matrix(y_class_val, pre) print ("L1正则化的linear SVM预测值: " , pre)print ("Linear SVM's confusion matrix: \n" , CM_linearSVM, "\n" , "-" *80 )probability = rbfSVM.predict_proba(X_val) print ("RBF核SVM预测概率: \n" , probability, "\n" , "-" *80 )from sklearn.svm import SVR, LinearSVRfrom sklearn.multioutput import MultiOutputRegressorfrom sklearn.metrics import mean_squared_error, r2_scorey = [[2 , 0.1 ], [5 , 0 ], [8 , 0.1 ], [11 , -0.1 ]] y_val = [[1 , 0.1 ], [14 , 0 ]] y_singleValue = [2 , 5 , 8 , 11 ] y_val_singleValue = [1 , 14 ] rbfSVR = SVR(C=10 , kernel="rbf" ) rbfSVR_Multi = MultiOutputRegressor(rbfSVR) rbfSVR_Multi.fit(X, y) linearSVR = LinearSVR(C=3.31 , max_iter=10000 ) linearSVR.fit(X, y_singleValue) prediction = rbfSVR_Multi.predict(X_val) MSE_rbfSVR = mean_squared_error(y_val, prediction) print ("rbfSVR's prediction: \n" , prediction)print ("rbfSVR's MSE: " , MSE_rbfSVR, "\n" , "-" *80 )R2_linearSVR = r2_score(y_val_singleValue, linearSVR.predict(X_val)) print ("Linear SVR's R2 score: " , R2_linearSVR)
运行结果:
参考:https://www.analyticsvidhya.com/bln/2017/09/understaing-support-vector-machine-example-code/
Python - sklearn官方文档:https://scikit-learn.org/stable/
6.3. MATLAB
MATLAB的“liblinear”与“libsvm”库的SVM/SVR算法都有相当不错的优化,二者皆由国立台湾大学林智仁教授设计开发,有数十种语言的发行版本,包括在R与Python上都有不错的性能,不仅仅在MATLAB适用;Liblinear较新,针对大数据设计,而Libsvm针对非线性分类SVM。
国立台湾大学 liblinear:https://www.csie.ntu.edu.tw/~cjlin/liblinear/
国立台湾大学 libsvm:https://www.csie.ntu.edu.tw/~cjlin/libsvm/