关于自动微分机制的数学证明放在文末,首先给出自动微分的程序实现。因为是我笔算进行推导的,可能存在谬误。
Python version: 3.12.4 numpy version: 1.26.4 sklearn version: 1.3.0
计算图定义
计算图(computational
graph)是一种被用于pytorch与tensorflow中进行自动微分以实现误差的反向传播、进而计算各参数梯度的技术,这使得我们可以方便地使用梯度更新神经网络的参数。其中,pytorch使用动态计算图设计,tensorflow使用静态计算图设计。
我们的实现中,计算图与自动微分系统被“嵌入”在了层的定义。pytorch在源码中定义了计算图基类,通过重载运算符等方法实现计算图的生成。
1 | import numpy as np |
基于计算图的MLP定义
1 | class MLP: |
训练过程
1 | X, y = make_moons(n_samples=1000, noise=0.1) |
打印:
Step 0, Loss: 0.6577937985199145 Step 10000, Loss: 0.00873273601484354 Step 20000, Loss: 0.00953517332872011 Step 30000, Loss: 0.0031810759662180698 Step 40000, Loss: 2.1824599140328784e-05 Step 50000, Loss: 0.00025276002897095404
1 | import matplotlib.pyplot as plt |

超平面可视化
可视化的原始代码来自唐亘先生的GitHub项目,在他的视频徒手实现多层感知器--人工智能的创世纪中对此有作演示。在他的可视化代码基础上,我做了若干更改,使数据图漂亮不少——至少,从我审美看的话。
1 | def draw_data(data): |
1 | draw_data([X, y]) |

1 | draw_model(draw_data([X, y]), mlp) |

自动微分机制的数学证明
在一个MLP中,假设batch_size = 1,以分子布局表示向量微分,记
numpy中对应操作符
*。
现在逐个讨论 batch_size大于np.sum(grad_output, axis=0)而非grad_output。这一步对其他梯度计算而言已经蕴含在矩阵
/ 张量乘法中了,但对偏置需要单独实现。
最后讨论
代码中的反向传播算法实际上正是该推理的程序实现。
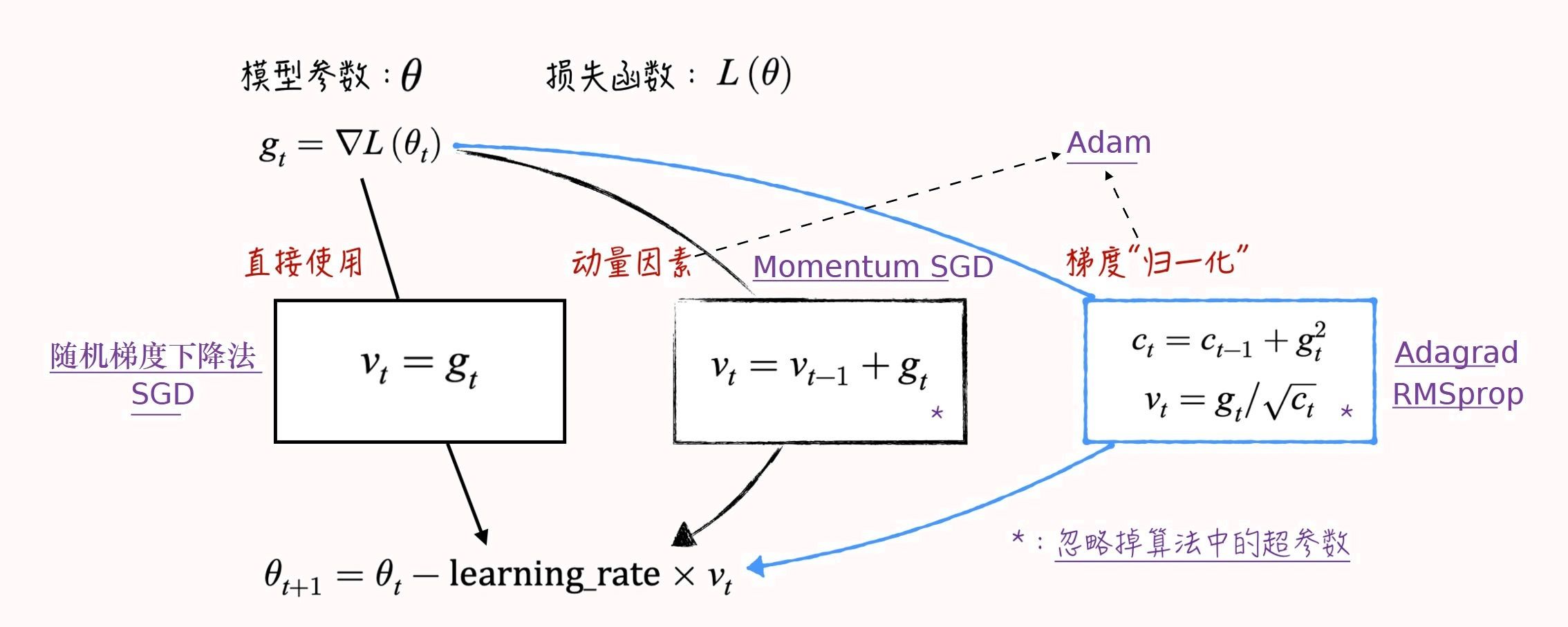
补充:关于批归一化技术与层归一化技术,偶然发现有一篇博客总结得十分不错,和我的见解高度一致,在此引用,
如果上述链接不可访问,可以在本站上访问链接网页的打印,